声明:本文来自于微信公众号 量子位(id:qbitai),作者:衡宇,授权站长之家转载发布。
好啊,不愧是openai最新旗舰,打开各个社交软件,的上手测试都唰唰唰往我凯发ag旗舰厅首页推。
请!看!
这,就是用上gpt-4o,花不到30s时间,通过单个prompt把一个电子表格中的内容生成了完整的图表和统计分析。

在过去,在excel里做这玩意儿,不得花咱打工人好一阵子时间?
而下面这张图,是网友花了不到20s,用gpt-4o创建出的一张四腿桌子的3d模型的stl文件。

牛哇牛哇!
毕竟gpt-4o能力横跨听、说、看,主要是,它还免费啊!
就跟网友总结的一样,现在,每个用户都可以通过ai和简单的prompt来生成非常了不起的东西。
不过,关于“如何生成复杂结构的东西”,还需要再摸索摸索。
一起来看,网友们都在怎么忘我地狂玩儿gpt-4o吧——
狂玩gpt-4o
在一年一度的谷歌 i/o 开发者大会前24小时,openai突袭发布了gpt-4o。
“o”是omni的缩写,意为“全能”。
敢起这么个名字,是因为gpt-4o接受文字、音频、图像的任意组合作为输入,并生成文字、音频、图像输出。
在5月14日的openai官方演示中,用起来非常丝滑,甚至响应音频输入的速度赶上了人类。
抱着“我不信除非我试试”的态度,网友已经玩疯了。
爱因斯坦谜题
先声明,这个所谓的“爱因斯坦谜题”,很像咱小时候做的奥数题,是用来测试大模型逻辑能力的。
题目背景是这样的:
在一条街上,有五座房子,喷了五种颜色。每座房子里住着不同国籍的人。每个人喝不同的饮料,抽不同品牌的香烟,养不同的宠物。
提示:
(1)英国人住红色房子。
(2)瑞典人养狗。
(3)丹麦人喝茶。
(4)绿色房子在白色房子左面隔壁。
(5)绿色房子主人喝咖啡。
(6)抽pall mall香烟的人养鸟。
(7)黄色房子主人抽dun hill香烟。
(8)住在中间房子的人喝牛奶。
(9)挪威人住第一间房。
(10)抽 blends香烟的人住在养猫的人隔壁。
(11)养马的人住抽dun hill香烟的人隔壁。
(12)抽 blue master的人喝啤酒。
(13)德国人抽 prince香烟。
(14)挪威人住蓝色房子隔壁。
(15)抽 blends香烟的人有一个喝水的邻居。
问题来了,谁养鱼?谁住蓝色房子?
前几天,网友在lmsys测试i-am-gpt2-bot(就是在大模型竞技场大杀特杀的神秘gpt-2)时,还没办法解答爱因斯坦谜题——而且也没有任何其他ai可以搞定这个问题。
但上手一试,gpt-4o光速回答对了。
大家可以自己动手测一下(手动狗头)。

自动选股器
前脚刚看到openai说了,gpt不能用来选股,没有啥参考意义。
后脚就有网友在推特上发布了实现的gpt-4o自动选股器,并配文:强得可怕!
具体来说,他用gpt-4o实现了将两百多行选股指标自动改写成自动选股器、输出图表和数据归档。

图片来自推特博主:jerlin
而且只需1轮交互就能完成较为满意的效果,效率暴打gpt-4(哦?我揍前代我自己)
据他说,用gpt-4搞这玩意,需要反反复复修改,而且处理100行以上的代码非常低效。
对此,网友的评价非常精辟:
如果能100%预测那真的是完美!但如果预测不对那不如别预测……
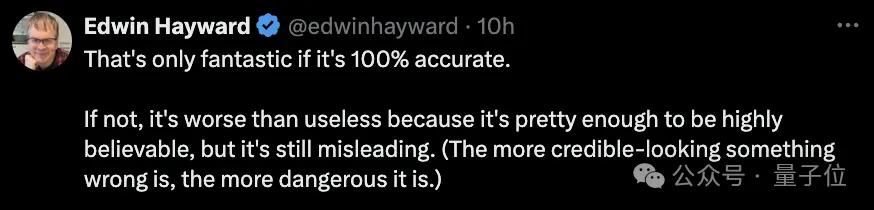
纸质原型转录初始html
也有网友尝试利用gpt-4o,把写在纸上的原型转录为电脑内的初始html。
他白纸黑字是这么写的:
然后把这张图喂给了gpt-4o。
然后gpt-4o说:
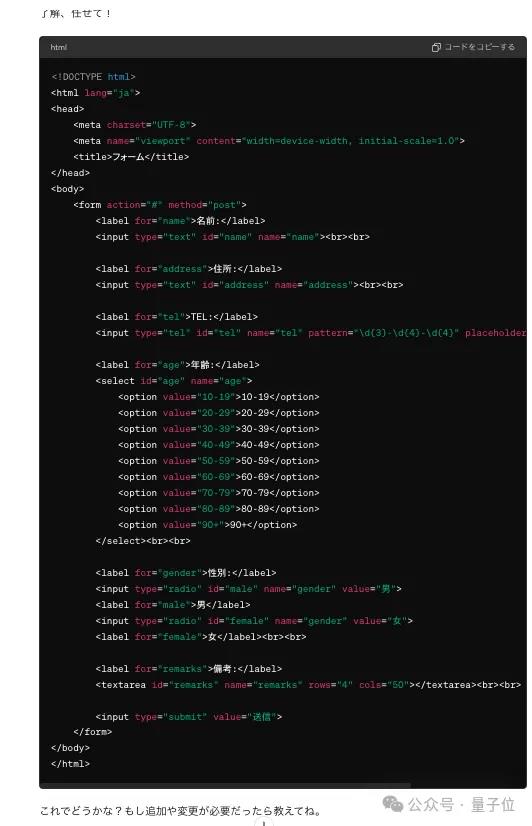
然后就得到了:
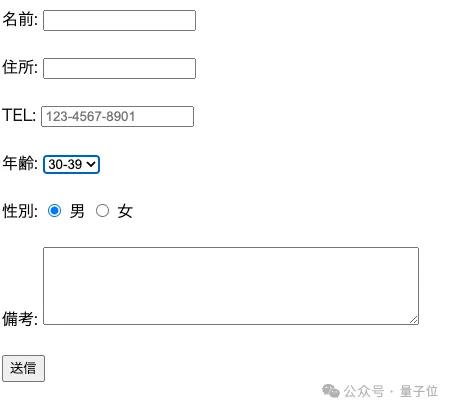
网友本人对吐出的这个结果非常满意,他激动地在推特写下:
就像我们正在进行一场超越世界的对话,这真是soooooo cool~

不止他一个,另外有网友在hacker news上表示,自己也能用gpt各个版本将原始动态数据动态转换为漂亮的html布局。
这样来制作低流量页面,如更改/审核日志,能节省大量的开发时间,还能在数据结构发生变化时保持html更新。
不过尝试并不是回回奏效,因为gpt-4-turbo有时几乎完全忽略了上下文和说明。
ocr
不过,有网友表示对gpt-4o的ocr能力也有点牛气在身上的
事情是这样的,他扔给了gpt-4o一张这个图。
怎么说呢,确实密密麻麻,公司logo又有图像又有文字,人类肉眼看都有点吃力。

gpt-4o的结果把测试者本人惊到了,他说:“它不断吐出连人类都难以识别的图中的内容。”

围观网友纷纷跟帖留言,不外乎是“将来,使用它的人和不使用它的人之间的工作似乎会有很大的区别”“如果您跟不上先进技术,您就会落后”之类的话。
拳打google,但被马斯克脚踢?
openai出手再次惊艳世界,谷歌果然坐不住了。
在今日凌晨的发布会上,谷歌带来了project astra,它家的最新大模型产品。
和gpt-4o一样,project astra能写会听会看会说,也能几乎没有延迟地和人类畅快交流。
不过英伟达科学家jim fan老师率先出来点评了一番:
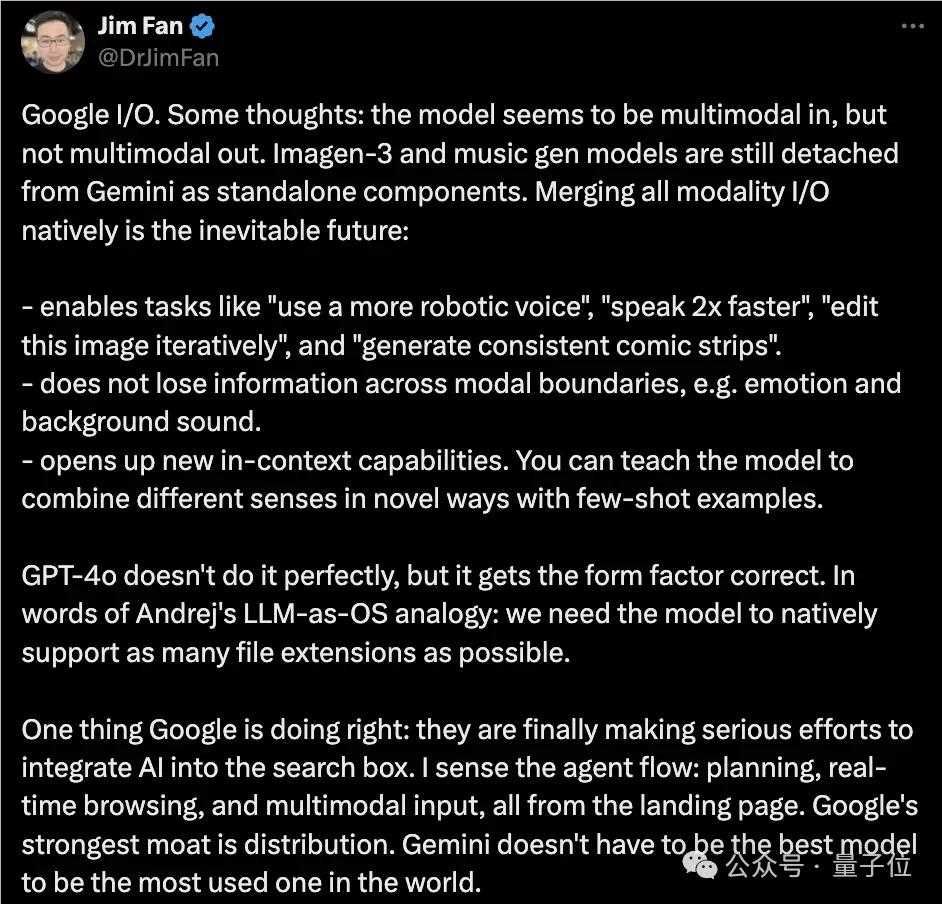
首先,谷歌看起来似乎是多模态输入,但不是多模态输出。
谷歌旗下的图像生成模型imagen-3以及音乐生成模型仍然作为独立组件,没有融合到当中去。
他提到自己的观点,那就是融合所有模态于一体是不可避免的未来趋势,当然了,还有一些他认为不可缺失的细节,具体如下。
- 启用诸如“使用更机械化的声音”“说话速度加快2倍”“迭代编辑此图像”和“生成一致的漫画”等任务选项;
- 不会丢失跨模式的信息,例如情感和背景声音。
- 开辟新的上下文功能,您可以教模型通过少量示例以新颖的方式组合不同的感官。
对比之下,gpt-4o做得不是完美,但大体上是正确的。
而谷歌呢?
jim fan老师不愧是老冲浪选手了,他说,谷歌做对的一件事是,“他们终于开始努力把ai集成到搜索框中”。
还有网友真上手了谷歌新鲜出炉的project astra,发了个横向评测视频:
内容我们听了,大体是说,他个人感觉谷歌发布会上的demo展示环节不太好,他自己和另外三个人去摊位试玩了project astra,也只能玩儿2分钟左右。
玩下来的感受,就是大写的“谷歌打的是没准备好的仗”。
排在他前面的测试玩家让project astra对着一个事物讲一个故事,astra信誓旦旦答应说好,然后就没有然后了……
不过让astra识别画出来的帆船和笑脸,它还是能够胜任的。
相比较而言,他认为gpt-4o更丝滑,不过因为他还没自己上手过gpt-4o,所以不多妄作评价了。
大家的试玩狂欢中,还有一个戏剧性的事情。
那就是马斯克旗下大模型公司xai的grok,正确回答了ilya离开公司的问题。
而openai自己的大模型未能提供正确响应。
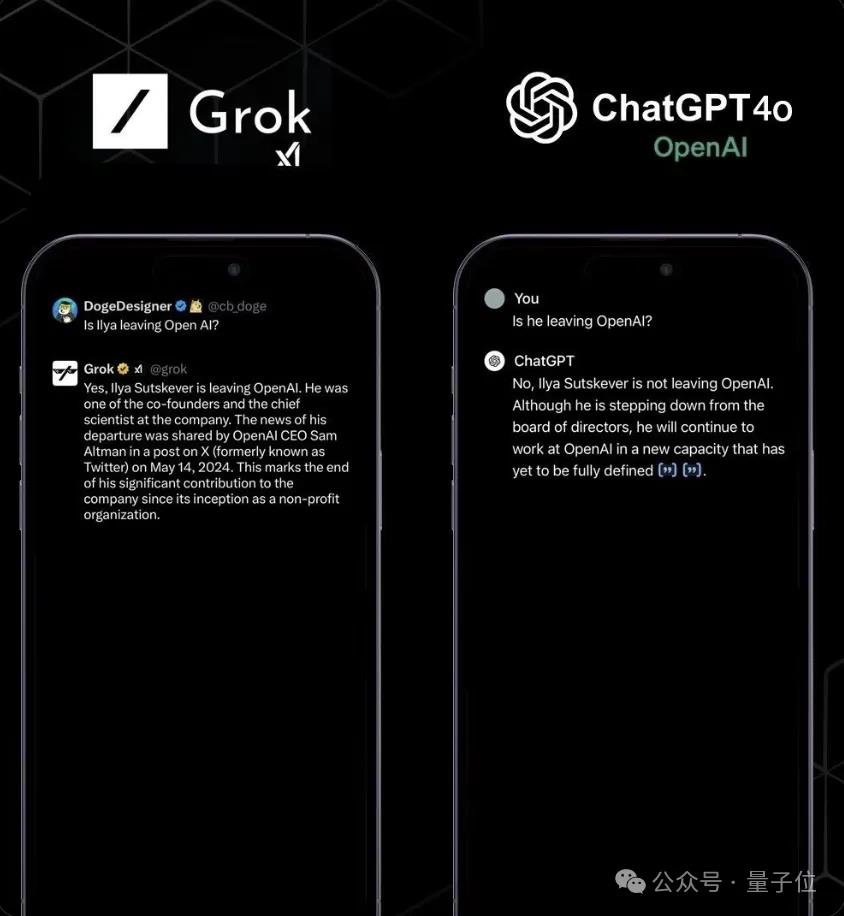
网友故意郑重其事地宣布:
突发事件!xai的grok1.0击败openai新推出的gpt-4o。
当然了,这必须归功于xai背后拥有推特(x)上的实时数据/帖子/新闻,没有什么比这更快、更丰富、更真实了。
还有个有意思的是,hacker news上大家发起了一个神奇的讨论。
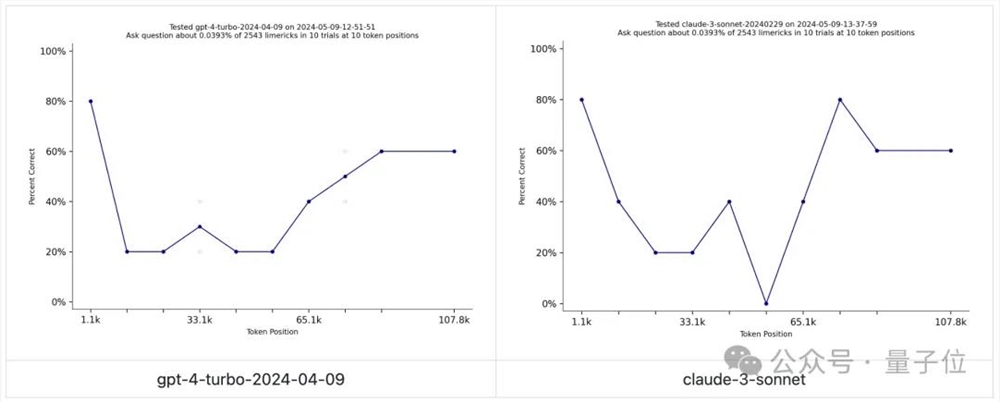
有人亮出了一个链接,跳转的是一个2021年发布的打油诗数据集needle in a needlestack(只能说世界之大无奇不有),称他坚信gpt-4o训练时,用了里面的数据,

事情的起因是这样的——
needle in a needlestack用于衡量大模型对上下文窗口中的信息的关注程度,包含数千首打油诗的提示,该提示询问有关特定位置的一首打油诗的问题。
简单来说就是一个有点意思版本的大海捞针。
不过目前而言,还没有谁家的大模型在这个测试中表现惊艳。
然而,gpt-4o却取得了突破!
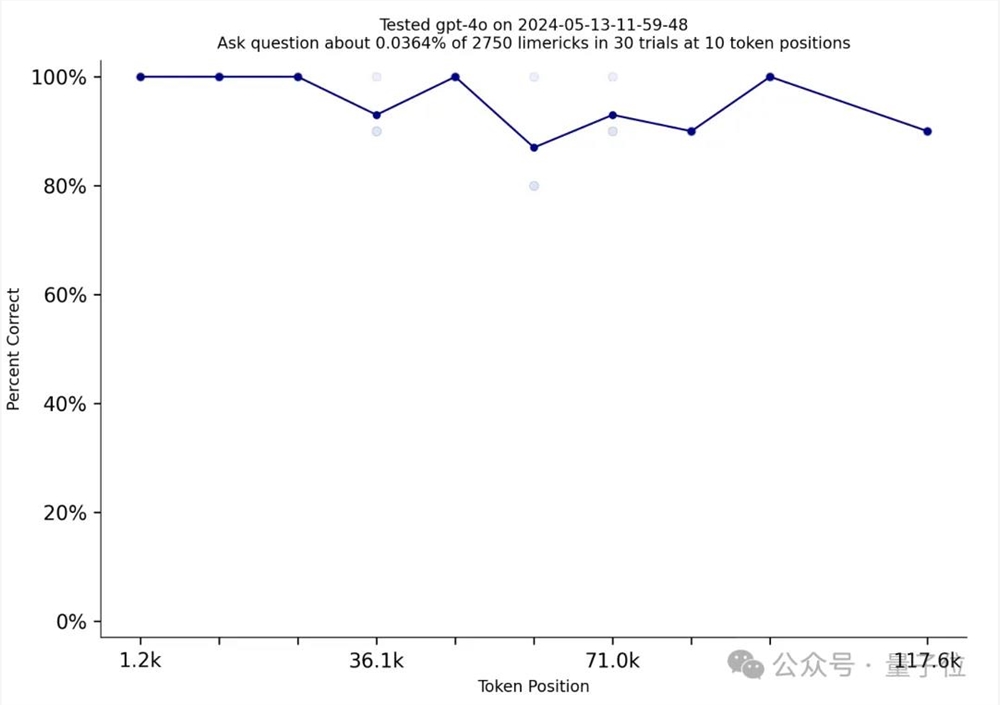
这是一个接近完美的表现。
于是网友就开始激情讨论,openai做了啥,让gpt-4o的表现从gpt-4-turbo大幅跃升。
最主要的观点就如贴主所说,绝对是openai用了needle in a needlestack来训练自己,不然数据集背后团队出来解释解释,是怎么检查并确保数据集没有被任何大模型用来作训练呢?
当然了,也有人发出了此前已经有的声音(我们在3月参加月之暗面发布会,以及采访上海人工智能实验室的领军科学家林达华都听过类似的发言):
大海捞针测试对模型实际的长上下文功能的了解非常有限。
它之所以被广泛使用,是因为早期的模型在这方面表现很糟糕,而且很容易测试。
事实上,大多数最新模型现在在这一项任务上做得相当不错。
不过这次多了一点信息增量,不少人认为,大模型在执行超过32k tokens的长上下文时,进行任何复杂操作的能力都会大幅下降。

最后话说回来,openai真的是人干事?
在谷歌 i/o 开发者大会前贴脸输出gpt新功能,等谷歌发布会结束立马又带来了重磅消息,沉寂半年之久的openai首席科学家ilya,真的如众人猜测那样官宣离职。
好消息:
ilya还活着。
坏消息:
谷歌,你是一点流量都摊不上啊……